All templates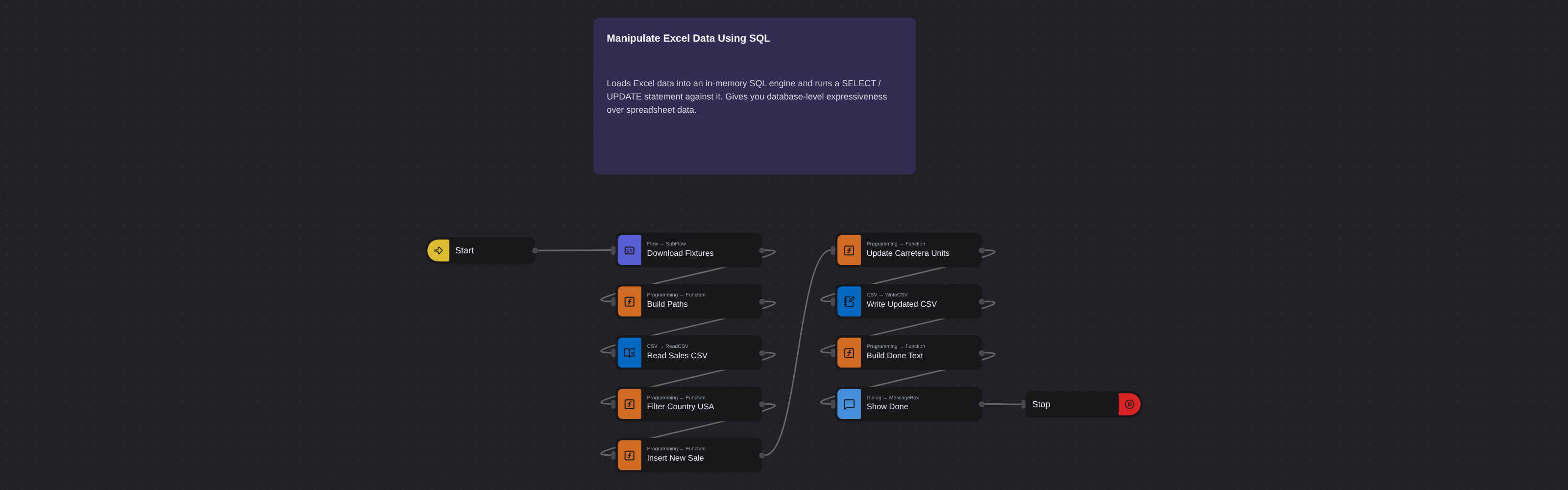
Excel AutomationAdvanced
Manipulate Excel Data Using SQL
Robomotion•Updated 8 months ago
Overview
Loads Excel data into an in-memory SQL engine and runs a SELECT / UPDATE statement against it. Gives you database-level expressiveness over spreadsheet data.
Manipulate Excel Data Using SQL
SQL queries can efficiently handle significant amounts of Excel data and reduce the need for complex data handling approaches. Robomotion allows you to access and update Excel spreadsheets using SQL queries.
What Manipulate Excel Data Using SQL can do
Download Fixturessubflow thenBuild Paths(Core.Programming.Function) setsmsg.excel_path = <fixtures>/sales.csvandmsg.output_csv_path = <fixtures>/sales_filtered.csv.Core.CSV.ReadCSVloads the sales CSV withoptHeaders: trueandoptSeparator: 'comma'intomsg.full_table.Filter Country USA(Core.Programming.Function) — SELECT-equivalent that stores rows wherer.Country === 'USA'intomsg.usa_rows.Insert New Sale(Core.Programming.Function) — INSERT-equivalent that pushes{ Country: 'Greece', Product: 'Paseo', Units: '2408' }ontomsg.full_table.rows.Update Carretera Units(Core.Programming.Function) — UPDATE-equivalent that rewrites any row withProduct === 'Carretera'toUnits: '1000'.Core.CSV.WriteCSVpersistsmsg.full_tableback tomsg.output_csv_path, thenCore.Dialog.MessageBoxtitledFlow run completedreports counts and the output path viamsg.dialog_text.
Behind the scenes
- The flow writes numeric columns as strings (
'2408','1000') becauseCore.CSV.ReadCSVwith headers returns string cells — keeping the same type avoids a schema mismatch whenCore.CSV.WriteCSVserialises the table. msg.usa_rowsis captured but not written to disk; it remains as a teaching beat for the SELECT step and is still available for downstream nodes.- The INSERT step appends to the end of
msg.full_table.rows, mirroring how a SQLINSERT INTOagainst an Excel range would land at the bottom of the used range. - Using in-memory table manipulation (rather than an ODBC driver) keeps the flow portable across OSes and removes the 32/64-bit driver mismatch that plagues ACE OLEDB setups.